Un scan automatique d’un fichier CSV de 10 000 lignes a permis d’identifier plusieurs types de données sensibles en quelques secondes, sans configuration manuelle.
Dans un contexte RGPD, ce type de détection permet de cartographier rapidement les données personnelles, d’identifier les zones à risque et de préparer une stratégie d’anonymisation avant tout usage en test, en analyse ou en IA.
Pourquoi scanner ses fichiers est devenu indispensable
La plupart des entreprises savent qu’elles manipulent des données personnelles. En revanche, elles savent rarement où elles se trouvent exactement, sous quelle forme elles circulent et dans quels fichiers elles sont réutilisées.
C’est particulièrement vrai pour les exports CSV, les fichiers Excel, les environnements de test et les jeux de données partagés entre équipes.
Au sens de la CNIL, une donnée personnelle est toute information se rapportant à une personne physique identifiée ou identifiable. Cela inclut par exemple un nom, une adresse email, un numéro de téléphone, une adresse IP ou un numéro de sécurité sociale.
Le sujet n’est donc pas seulement technique. Il est aussi réglementaire. Le RGPD impose notamment de documenter les traitements de données personnelles et de mettre en place des mesures de sécurité adaptées au risque. En cas de violation de données, la notification à l’autorité de contrôle doit, lorsque c’est requis, intervenir dans les 72 heures.
Phrase clé à retenir :
On ne peut pas protéger correctement des données que l’on n’a pas identifiées.
Cas concret : scan d’un fichier CSV de 10 000 lignes
Pour illustrer le sujet, nous avons pris un fichier CSV(téléchargez le fichier et testez-le directement sur notre démo en ligne) de type base clients contenant 10 000 lignes et 28 colonnes, puis lancé un scan automatique sans paramétrage préalable.
Contexte du test
| Format | CSV |
| Volume | 10 000 lignes |
| Structure | 28 colonnes |
| Type de données | Jeu de données de démonstration de type base clients |
| Mode de traitement | Scan local, sans envoi vers un service cloud |
| Configuration requise | Aucune |
L’objectif n’était pas seulement de repérer les colonnes évidentes, comme email ou telephone, mais aussi de vérifier si des données personnelles pouvaient être détectées dans des champs moins explicites comme notes (téléchargez le fichier).
Résultat : plusieurs types de données sensibles détectés
Le scan a permis d’identifier les catégories suivantes :
- Nom / prénom
- Adresse email
- Numéro de téléphone
- Adresse postale
- Code postal
- Ville
- Date de naissance
- Numéro de sécurité sociale
- IBAN
- Numéro de carte bancaire
- Adresse IP
- Identifiant client
- Nom d’entreprise
- URL
- …
Ce que ce résultat montre
Un fichier qui semble « simple » peut en réalité contenir plusieurs niveaux de sensibilité :
- des données d’identification directe
- des données de contact
- des données financières
- des identifiants techniques
- des informations réutilisables pour profiler ou réidentifier une personne
Définition claire :
La cartographie des données sensibles consiste à repérer, classifier et documenter les champs contenant des données personnelles ou des informations à risque.
Comment fonctionne la détection automatique
Une détection crédible ne repose pas sur un seul signal. Elle combine généralement plusieurs niveaux d’analyse.
1. Analyse des noms de colonnes
Première étape : le système évalue les intitulés de colonnes.
Exemples :
emailemail_facturationclient_phonedobibanlast_login_ip
Cette étape permet d’identifier rapidement les colonnes dont le nom est déjà explicite.
2. Analyse des valeurs
Deuxième étape : le système vérifie le contenu réel des colonnes.
Exemples :
- format d’une adresse email
- structure d’un numéro de téléphone
- présence d’un IBAN
- motif d’une adresse IP
- chaîne compatible avec un numéro de sécurité sociale
3. Croisement sémantique
Enfin, la détection la plus utile est celle qui combine :
- le nom de la colonne
- le type de valeurs observées
- le contexte métier éventuel
C’est ce qui permet de repérer une colonne mal nommée mais sensible dans les faits comme la colonne « notes » du fichier.
Phrase clé à retenir :
Une colonne mal intitulée peut contenir une donnée hautement sensible.
Le vrai enjeu : rendre visible l’invisible
Dans la plupart des organisations, le risque ne vient pas uniquement de la base de production. Il vient surtout des copies, des exports et des réutilisations.
On retrouve souvent des données sensibles dans :
- les environnements de test
- les exports CSV envoyés par email
- les fichiers partagés entre services
- les sauvegardes
- les jeux de données utilisés pour un projet IA
- les journaux applicatifs
Pourquoi ce sujet concerne directement le RGPD
Le RGPD ne demande pas seulement de « sécuriser » les données au sens large. Il demande de comprendre les traitements, les risques et les mesures mises en place.
Dans la pratique, cela implique au minimum :
- identifier les données personnelles
- savoir où elles se trouvent
- limiter leur circulation inutile
- appliquer des mesures techniques et organisationnelles adaptées
- documenter ce qui a été fait
Le registre des traitements prévu par l’article 30 et les mesures de sécurité prévues par l’article 32 supposent une connaissance minimale des données manipulées. Sans détection initiale, cette connaissance reste partielle.
Pourquoi scanner un fichier CSV avant tout partage ou usage en test ?
Scanner un fichier CSV avant son partage permet d’éviter une erreur très fréquente : considérer un export comme « technique » alors qu’il contient encore des données personnelles exploitables.
Réponse directe
Parce qu’un fichier partagé en interne, transmis à un prestataire ou réutilisé dans un environnement de test peut contenir des données personnelles visibles, recoupables ou réidentifiables.
Le scan est donc la première étape logique avant :
- une anonymisation
- une pseudonymisation
- une transmission à un tiers
- une réutilisation pour des tests
- une exploitation pour un projet data ou IA
Cas d’usage réaliste en entreprise
Une équipe produit prépare une recette applicative à partir d’un export CRM.
Le fichier est considéré comme « interne », donc peu risqué. Il est transmis à une équipe technique pour accélérer les tests.
Après scan, plusieurs catégories apparaissent :
- emails professionnels
- numéros de téléphone
- identifiants clients
- adresses IP de connexion
- dates de naissance présentes dans une colonne secondaire
Dans ce scénario, le risque ne vient pas d’une intention malveillante. Il vient d’un manque de visibilité.
La bonne séquence n’est pas :
exporter → partager → espérer
La bonne séquence est :
scanner → qualifier → anonymiser → tracer →partager si nécessaire
Comment industrialiser la détection de données sensibles
Étape 1 : ne pas se limiter à la production
Les fichiers à vérifier ne sont pas seulement les bases principales.
Il faut aussi inclure :
- les environnements de développement
- les environnements de test
- les exports métier
- les jeux de données d’analyse
- les sauvegardes
- certains logs
Étape 2 : automatiser la détection
Un contrôle manuel peut aider ponctuellement, mais il ne suffit pas à l’échelle.
L’automatisation permet :
- une détection plus homogène
- une meilleure répétabilité
- moins d’angles morts
- une base de travail claire pour les équipes sécurité, data et conformité
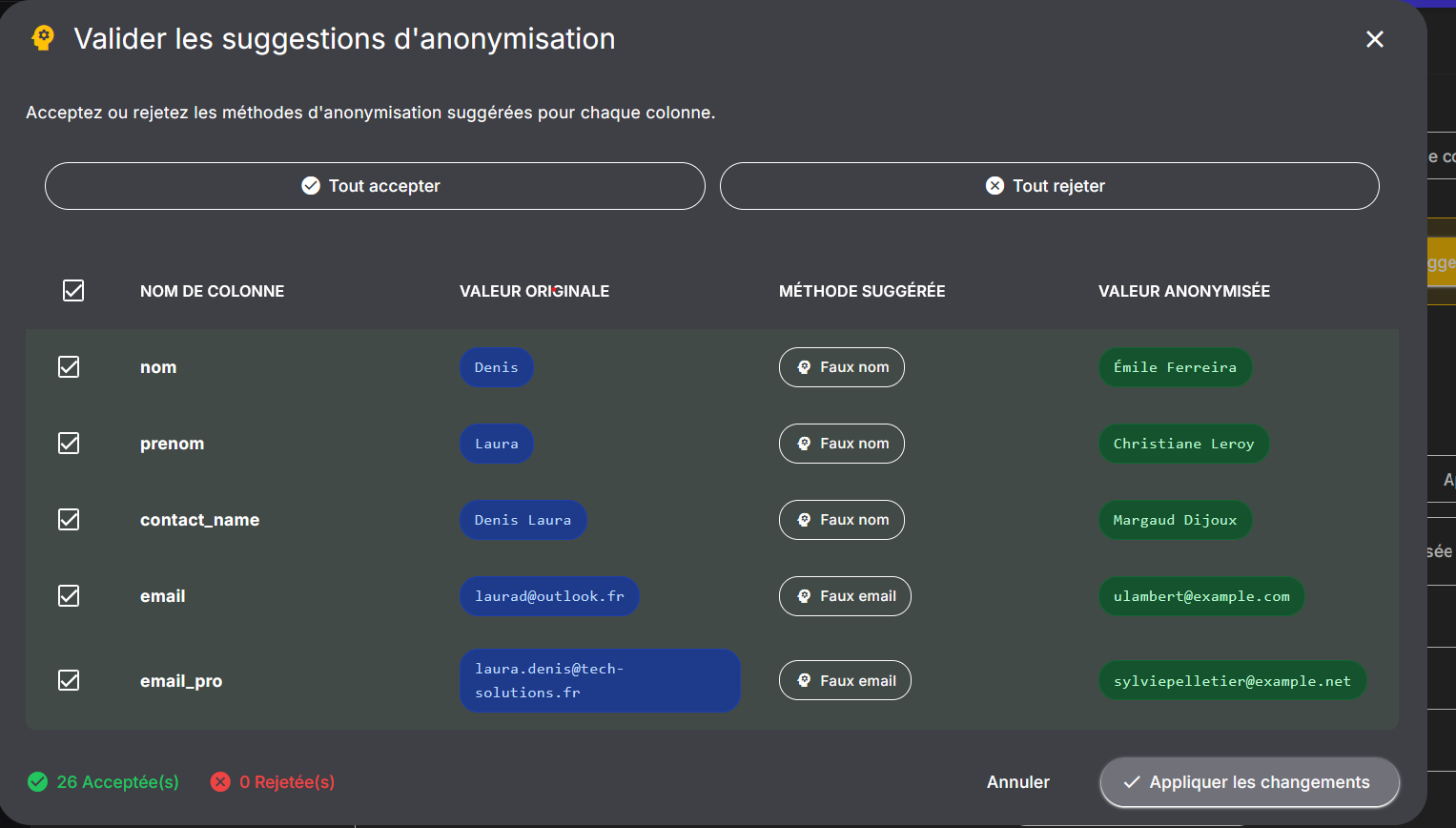
Étape 3 : enchaîner avec l’anonymisation
Identifier les données n’est que la première étape.
Ensuite, il faut choisir la méthode adaptée :
- masquage
- suppression
- génération de valeurs cohérentes
- pseudonymisation
- anonymisation irréversible selon l’usage cible
Au-delà de la détection et de l’anonymisation, il faut également une traçabilité complète
Une solution complète doit également permettre de générer un rapport structuré des traitements réalisés autrement dit, avoir une traçabilité complète des opérations effectuées:
- quelles données ont été détectées
- quelles méthodes ont été appliquées
- quand le traitement a été exécuté
- sur quels fichiers ou tables
Ce type de rapport constitue une base utile pour documenter les actions réalisées dans une logique de conformité RGPD.
Important :
Ce rapport ne remplace pas un DPO ni un audit de conformité, mais il facilite la traçabilité et la préparation des contrôles.
→C’est précisément ces différentes étapes que nous mettons en œuvre chez Nymdata en détectant les données sensibles, puis en proposant des méthodes d’anonymisation et enfin en générant un rapport détaillé des opérations réalisées (qui, quoi, quand, comment).
Conclusion
Scanner automatiquement un fichier CSV permet de transformer une intuition vague en cartographie exploitable.
Pour un DPO, un RSSI ou un CTO, l’enjeu n’est pas seulement de détecter des colonnes sensibles. Il est de pouvoir décider rapidement :
- ce qui peut être utilisé
- ce qui doit être anonymisé
- ce qui ne doit pas circuler
- ce qui doit être documenté
Phrase clé à retenir :
La conformité commence souvent par une opération simple : voir enfin ce que contient réellement un fichier.
FAQ
Qu’est-ce qu’une donnée personnelle dans un fichier CSV ?
C’est toute information relative à une personne physique identifiée ou identifiable. Cela peut être un nom, un email, un téléphone, une adresse IP, un identifiant de connexion ou un numéro administratif.
Un scan de fichier suffit-il pour être conforme au RGPD ?
Non. Le scan sert à cartographier les données présentes. Il doit ensuite être complété par des mesures de sécurité, une gestion des accès, une documentation des traitements et, selon les cas, une anonymisation ou une pseudonymisation.
Pourquoi les environnements de test sont-ils sensibles ?
Parce qu’ils contiennent souvent des copies de données issues de la production, avec un niveau de protection inférieur ou des usages plus différents.
Quelle différence entre pseudonymisation et anonymisation ?
La pseudonymisation réduit l’identification directe mais reste réversible dans certaines conditions. L’anonymisation vise à rendre la réidentification impossible.
Pourquoi détecter les données avant un projet IA ?
Parce qu’un dataset exploitable pour l’IA peut aussi contenir des données personnelles ou des signaux réidentifiants. Sans cartographie préalable, le risque juridique et opérationnel augmente.
Passez à l’action
Vous voulez identifier rapidement les données sensibles présentes dans vos fichiers ou vos bases avant un usage en test, en audit ou en projet IA ?
NymData permet de :
- détecter automatiquement les données sensibles
- anonymiser les données de manière cohérente
- générer un rapport détaillé des traitements réalisés
Ce rapport constitue une base exploitable pour documenter vos actions dans une démarche de conformité.
Téléchargez le fichier utilisé lors des tests et testez-le directement sur notre démo en ligne




