L’anonymisation des données ne se résume pas à masquer des informations.
Il existe plusieurs méthodes, chacune adaptée à un usage précis : test, analyse, partage ou conformité RGPD.
→ Le choix de la méthode conditionne :
- le niveau de sécurité
- la possibilité de ré-identification
- l’exploitabilité des données
Ce guide présente les principales techniques d’anonymisation et leurs cas d’usage.
Pourquoi il existe plusieurs méthodes d’anonymisation
Toutes les données ne présentent pas le même niveau de risque.
→ Une donnée bancaire, une adresse email ou un code postal ne se traitent pas de la même manière.
Le RGPD ne demande pas une méthode unique, mais une approche adaptée et proportionnée.
Une bonne anonymisation dépend du contexte, pas d’une seule technique.
Qu’est-ce qu’une méthode d’anonymisation ?
Une méthode d’anonymisation est une technique permettant de transformer des données personnelles afin d’empêcher l’identification d’un individu.
L’objectif est double :
- protéger la vie privée
- conserver la valeur des données
L’anonymisation consiste à modifier ou supprimer les informations identifiantes pour empêcher toute identification directe ou indirecte.
Les principales méthodes d’anonymisation
1. Suppression (ou suppression de données)
Principe :
→ supprimer complètement la donnée sensible
Exemple :
- nom → supprimé
- numéro de sécurité sociale → supprimé
Avantages :
- sécurité maximale
- irréversibilité
Limites :
- perte totale d’information
- inutilisable pour analyse
2. Masquage (data masking)
Principe :
→ cacher la donnée tout en conservant son format
Exemple :
- email → j****@mail.com
- téléphone → 06 ** ** ** 78
Le masquage consiste à remplacer les valeurs par des données fictives ou masquées
Avantages :
- simple à mettre en place
- lisible visuellement
Limites :
- peu exploitable pour tests
- risque si masquage partiel
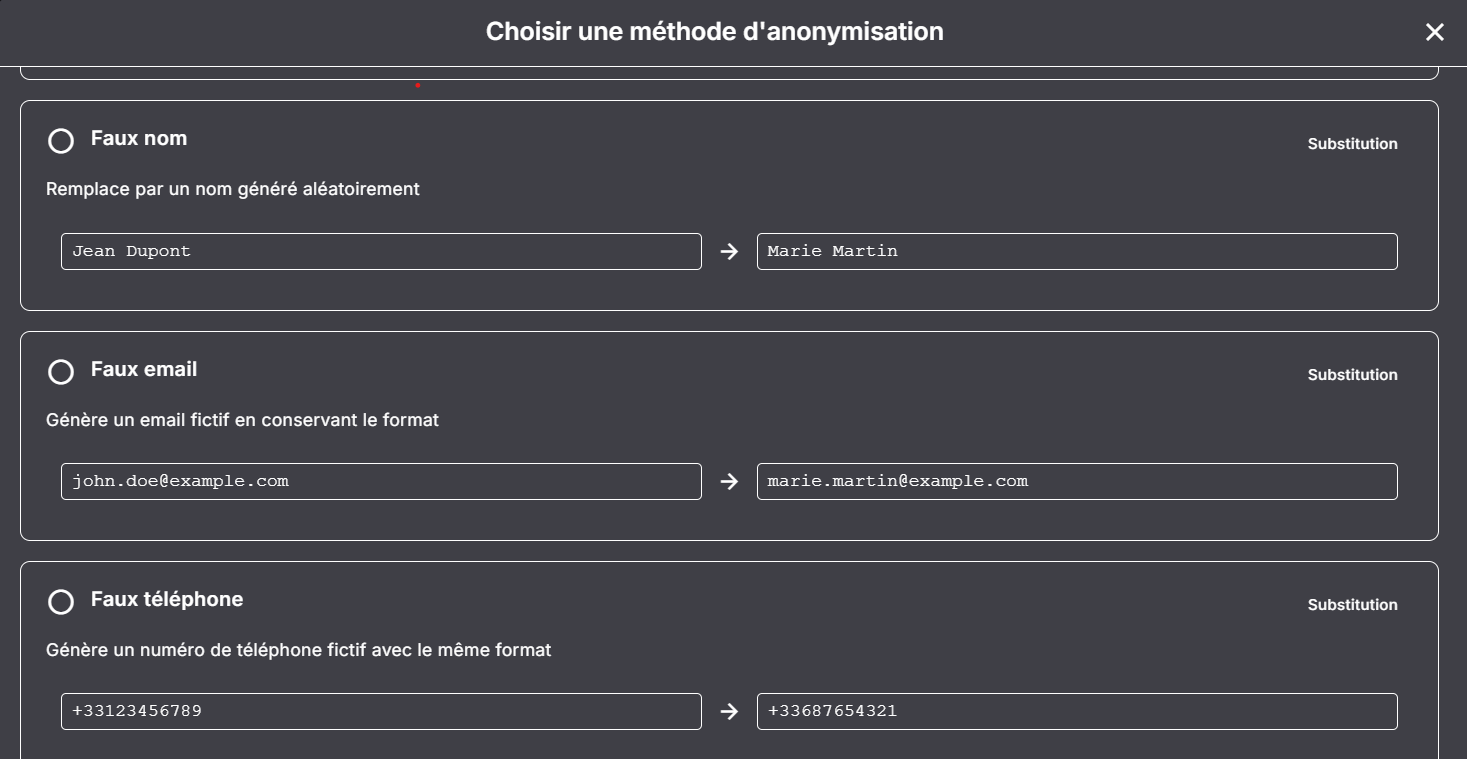
3. Substitution (fake data)
Principe :
→ remplacer la donnée réelle par une donnée fictive réaliste
Exemple :
- Jean Dupont → Marc Leroy
- Paris → Lyon
Avantages :
- données exploitables
- idéal pour les environnements de test
Limites :
- nécessite des générateurs cohérents
- plus complexe
4. Généralisation
Principe :
→ réduire la précision de la donnée
Exemple :
- 1987 → 1980–1990
- 75016 → 75
La généralisation consiste à remplacer des données précises par des catégories plus larges
Avantages :
- conserve la valeur statistique
- utile pour analyses
Limites :
- risque de ré-identification si mal combinée
5. Agrégation
Principe :
→ regrouper les données pour obtenir uniquement des résultats globaux
Exemple :
- données individuelles → moyenne ou total
Avantages :
- très sécurisant
- idéal pour reporting
Limites :
- perte de granularité
6. Randomisation (perturbation)
Principe :
→ modifier les données de manière aléatoire
Exemple :
- salaire 3000 → 3100
- âge 42 → 40
Avantages :
- protège l’identité
- conserve des tendances
Limites :
- altère la précision
7. Hachage
Principe :
→ transformer une donnée en empreinte irréversible
Exemple :
- email → hash cryptographique
Avantages :
- irréversible
- utile pour déduplication
Limites :
- non exploitable directement
- vulnérable sans sécurisation (salt)
8. Données synthétiques
Principe :
→ générer des données artificielles sans lien avec les données réelles
Exemple :
- base clients entièrement générée
Les données synthétiques sont créées artificiellement sans lien avec les données d’origine
Avantages :
- aucun risque RGPD
- très puissant pour IA
Limites :
- complexité
- nécessite modélisation
Comment choisir la bonne méthode
Le choix dépend de votre usage :
- test → substitution
- analyse → généralisation / agrégation
- sécurité maximale → suppression
- IA → données synthétiques
→ Il est souvent nécessaire de combiner plusieurs méthodes.
Pourquoi la détection est indispensable avant anonymisation
Avant de choisir une méthode, il faut savoir :
→ quelles données sont sensibles
Sans cette étape :
- certaines données restent exposées
- l’anonymisation est incomplète
Pour approfondir, lisez notre article.
Erreur fréquente : utiliser une seule méthode
Une seule technique ne suffit pas.
Exemple :
- masquer un nom
- mais laisser date de naissance + code postal
→ ré-identification possible
Une anonymisation efficace combine plusieurs méthodes.
Pourquoi ces méthodes sont clés pour le RGPD
Le RGPD impose :
- minimisation des données
- protection des données personnelles
- réduction des risques
L’anonymisation permet :
- de sortir du périmètre RGPD
- de réduire l’exposition aux risques
Cas concret
Une entreprise veut utiliser une base clients pour :
- tests applicatifs
- analyse marketing
Solution :
- noms → substitution
- emails → fake data
- dates → généralisation
- données sensibles → suppression
→ résultat : données exploitables et sécurisées
Conclusion
Il n’existe pas une seule méthode d’anonymisation.
→ Il existe des méthodes adaptées à chaque usage.
Le véritable enjeu n’est pas de masquer les données.
→ C’est de choisir la bonne combinaison.
L’anonymisation est une stratégie, pas une simple technique.
FAQ
Quelle est la meilleure méthode d’anonymisation ?
Il n’y en a pas une seule. Tout dépend du contexte et de l’usage.
Peut-on combiner plusieurs méthodes ?
Oui. C’est même recommandé.
Le masquage suffit-il ?
Cela dépend du contexte mais non en général. Il doit être combiné avec d’autres techniques.
Les données anonymisées sont-elles encore soumises au RGPD ?
Non, si l’anonymisation est irréversible.
Quelle méthode pour les tests ?
La substitution est la plus adaptée.
Passez à l’action
Vous souhaitez choisir automatiquement les bonnes méthodes d’anonymisation selon vos données ?
NymData permet de :
- détecter les données sensibles
- proposer une méthode adaptée par colonne
- anonymiser à grande échelle
- générer un rapport de conformité




