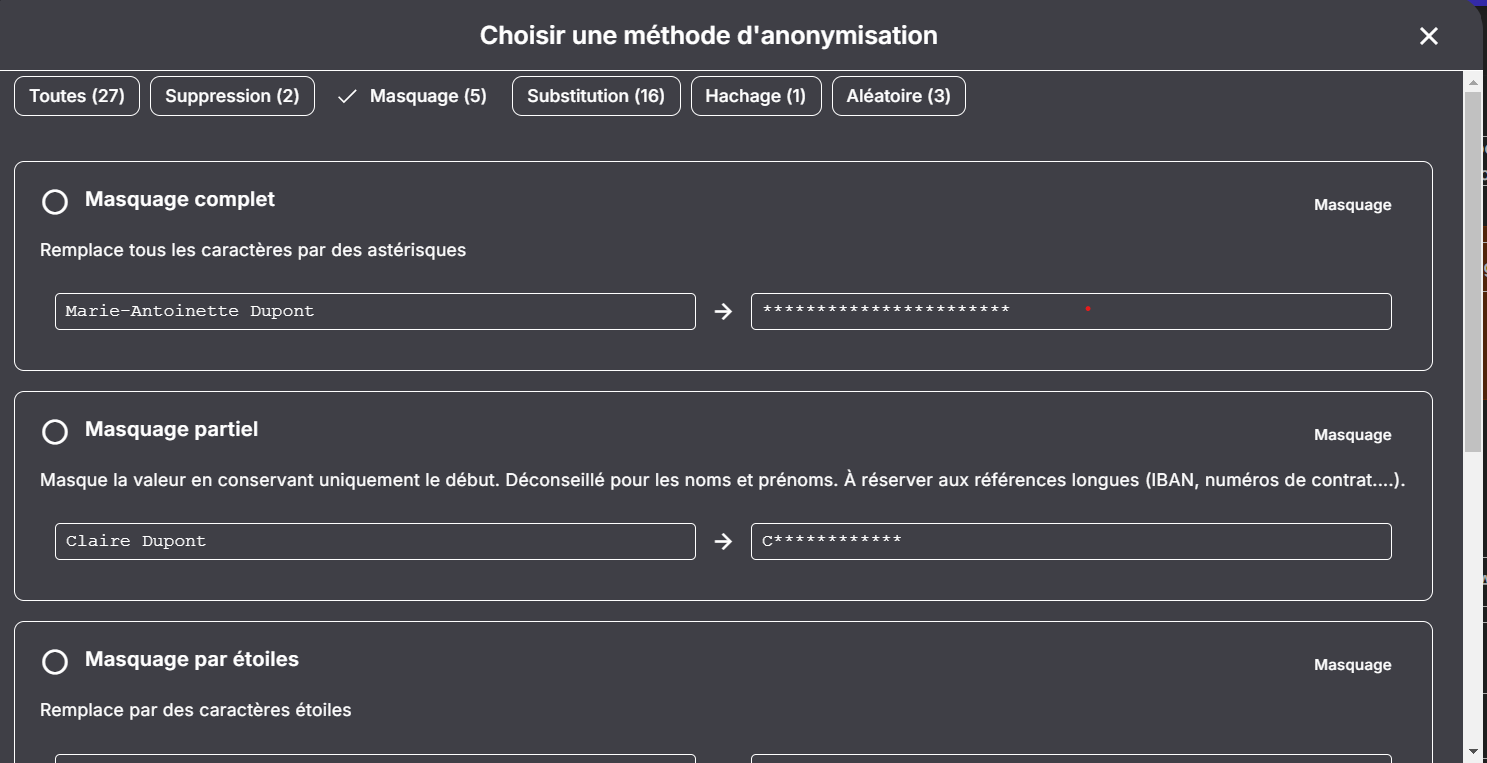
Remplacer des données par des “****” est une erreur fréquente en anonymisation.
Cette approche donne une illusion de sécurité, tout en rendant les données inutilisables.
Une anonymisation efficace repose sur un choix :
quelle méthode utiliser, pour quel usage, sur quelle donnée.
Le problème : une anonymisation qui ne sert à rien
Dans de nombreuses organisations, l’anonymisation se résume à ceci :
UPDATE clients SET nom = '****', email = '****';
Cette approche pose plusieurs problèmes :
→ les données deviennent inutilisables
→ les formats sont cassés (email invalide, téléphone incohérent)
→ les relations entre données disparaissent
Résultat : les équipes ne peuvent plus tester ni analyser correctement.
Une anonymisation mal conçue dégrade les données sans réduire réellement le risque.
L’erreur fondamentale : croire qu’il existe une seule méthode
L’anonymisation n’est pas une technique unique.
C’est une combinaison de méthodes adaptées à un contexte précis.
Le vrai sujet n’est pas “comment anonymiser”, mais :
→ pourquoi anonymiser
→ pour quel usage
→ avec quel niveau de risque
Les 5 approches qui couvrent 95% des cas
Il existe en réalité de nombreuses techniques d’anonymisation, avec des niveaux de complexité différents.
👉 Un guide complet des méthodes est détaillé ici
1. Supprimer
→ utile si la donnée ne sert pas
✔ sécurité maximale
❌ inutilisable
2. Masquer
→ utile pour affichage
✔ lisible
❌ non exploitable
3. Substituer (données fictives)
→ utile pour test / développement
✔ réaliste
✔ exploitable
✔ cohérent
👉 c’est la méthode la plus utilisée en pratique
4. Généraliser
→ utile pour analyse / BI / IA
✔ conserve les tendances
❌ perte de précision
5. Hacher
→ utile pour identifiants
✔ irréversible
✔ permet la correspondance
❌ non lisible
Ce qu’il ne faut pas confondre
Le chiffrement est souvent présenté comme une solution.
En réalité, il s’agit d’une pseudonymisation.
La donnée reste réversible.
👉 Pour comprendre précisément la différence, consultez notre article :
Le vrai problème : anonymiser sans savoir quoi anonymiser
Dans la pratique, les erreurs viennent rarement de la méthode.
Elles viennent du fait que certaines données ne sont jamais identifiées :
→ champs libres
→ colonnes mal nommées
→ données cachées
👉 C’est pourquoi la détection des données sensibles doit précéder toute anonymisation
Pourquoi le choix de la méthode est critique
Une mauvaise méthode peut :
→ laisser des données ré-identifiables
→ casser les usages métier
→ créer un faux sentiment de conformité
Dans de nombreux cas, le risque vient des données invisibles.
👉 Par exemple, certaines colonnes sensibles passent totalement inaperçues dans les bases de test si elles ne sont pas analysées correctement
Conclusion
Anonymiser ne consiste pas à appliquer une règle uniforme.
C’est une décision :
→ technique
→ métier
→ réglementaire
Chaque donnée doit être traitée en fonction de son usage.
Une anonymisation efficace protège les données sans détruire leur valeur.
FAQ
Quelle est la meilleure méthode d’anonymisation ?
Il n’y a pas de méthode unique. Tout dépend de l’usage.
Peut-on combiner plusieurs méthodes ?
Oui, c’est recommandé.
Le hachage suffit-il ?
Non, cela dépend du type de donnée.
Le chiffrement est-il une anonymisation ?
Non, il s’agit d’une pseudonymisation.
Passez à l’action
Vous souhaitez appliquer les bonnes méthodes d’anonymisation sur vos données ?
NymData permet de :
→ détecter automatiquement les données sensibles
→ appliquer des méthodes adaptées
→ générer un rapport des traitements




